Pareidolia Effect on Facial Detection Algorithms
Link to Repo:
What is Pareidolia?
Pareidolia is defined as seeing recognized objects or patterns in random or unrelated objects. In relation to facial recognition it is the effect of seeing faces in inanimate objects.
Methods:
I found 100 images that induced pareidolia of faces and used Labelbox to create my predicted locations around where the pareidolia faces are in the image. There were a total of 116 pareidolia faces to locate in the 100 test images. I used images with one or more pareidolia faces in them. The images consisted of pareidolia faces in trees, rocks, food, and mountains. In facial recognition these images are actually considered false positives if facial detection models detect these pareidolia faces as real human faces. I first tested the images on a cascade classifier with a pretrained model from OpenCV's github repo of pretrained models. The pretrained model I used was the haarcascade frontal face default model. I then also tested it on a deep learning model: Multi-Task Cascaded Convolutional Neural Network.
Cascade Classifier:
A feature based face detection algorithm where models are organized into a hierarchy of increasing complexity, hence a cascade. Simpler classifiers act like a coarse filter and operate directly on candidate face regions. Complex classifiers then come in and operate only on those candidate regions selected by the simpler classifiers that show the most promise as faces.
Multi-Task Cascaded Convolutional Neural Network:
A deep learning model that incorporates landmark detection: detection of facial features such as eyes, nose, and a mouth. The network uses a cascade structure of three networks.
STEP 1->
Image pyramid creation: The image is rescaled to a range of different sizes
STEP 2->
First model (Proposal Network aka P-Net): this network proposes candidate facial regions
STEP 3->
Second model (Refine Network aka R-Net): this model filters the bounding boxes for the best one that has promise of being a face
Increasing Complexity
STEP 4->
Third model (Output Network aka O-Net): this model performs facial landmark detection on the output of the R-Net.
Results:
Of the 100 images in the testing set the simple cascade classifier was able to detect pareidolia faces in 58 of those images. The green boxes are my predicted face locations and the red boxes were what the model detected as human faces. The simpler classifier was able to detect the more subtle pareidolia faces that I did not predict.






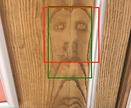






These were the images that the model detected faces in the same area as my predictions from the simple model. The model was able to detect the more simpler looking pareidolia faces in the testing dataset (ie two dots as eyes and a line as a mouth). In some of the images you can also see that the model detected very subtle pareidolia faces that I was unable to detect in my predictions. These subtle faces are shown with pink arrows.
These were the images that detected faces in different areas compared to my predictions from the simple model. The faces it detected were very subtle and tiny in comparison to the pareidolia faces that I predicted. I added pink arrows to the pareidolia faces that I missed in my predictions, but was detected by the model. However, the model was unable to detect the pareidolia faces that I predicted it would detect. The model was able to detect the more simpler looking faces in the testing dataset.










Let us take a deeper look into the more complex model to see if the results are any different.




MTCNN RESULTS:
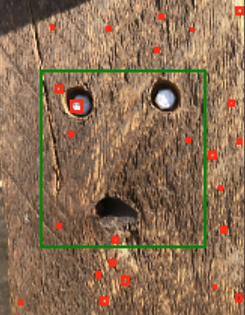
Below are the 16 images that the MTCNN model detected as either a human face or a facial feature, and among these 16 images it showed a few similar trends among the images. I discuss these trends alongside the images that show these trends. The green boxes are my predicted pareidolia face locations and the red boxes were what the model detected as human faces. The red dots were the landmark features detected by the model. It could detect eyes, the tip of the nose, and left and right corners of the mouth.

Figure 1.
These images show how the model failed to detect the pareidolia faces and instead detected 4 (right) and 2 (left) tiny facial features in its landmark detection phase (the red dots).

Figure 2.

Figure 3.
This image shows how the model detected a face in the same location as my prediction, however its nose and mouth corners landmark detection dots are off. Its eyes dots are correct in terms of the pareidolia face.

Figure 4.
These images show how the model detected the pareidolia faces and their facial features in its landmark detection phase (the red dots) in the same locations as my predictions.

Figure 8.

Figure 5.


Figure 7.
Figure 6.


Figure 10.
Figure 9.
This image shows how the model detected a face in the same location as my prediction and even detected a tiny face that I missed in my predications, which is incredible! Its landmark facial feature dots seam reasonable in relation to the pareidolia face. It detected a face in the lower right corner, but I am unable to see the supposed pareidolia face there.


Figure 11.
These images show how the model detected faces in areas that are off from my predictions and the supposed faces' features in its landmark detection phase (the red dots) seem unreasonable.

Figure 12.
Figure 13.

Figure 14.

This image show how the model detected the multiple pareidolia faces in the same locations as my predictions in the image and its detected facial features seem reasonable in relation to the pareidolia faces.
Figure 15.
This image show how the model detected only one of the multiple pareidolia faces that I had predicted in the image and its nose landmark seems off. It missed the pareidolia face with nostrils as its nose, so maybe the model cannot identify faces in this angle.
Figure 16.

This image show how the model detected the pareidolia face in the rocks even though the pareidolia face is a side profile. Its facial features seem reasonable in relation to the pareidolia face.
Figure 17.
Some images that the MTCNN model did not detect faces in:

Figure 18.

Figure 20.

Figure 22.

Figure 19.

Figure 21.

Figure 23.
Discussion:
Out of the 100 test images the simple classifier detected 19 of my predicted pareidolia faces. The simple classifier detected a multitude of pareidolia faces that I was unable to identify while labeling the images. It was able to detect the more subtle tiny pareidolia faces compared to the more obvious larger pareidolia faces.
Out of the 100 test images MTCNN found:
-
12 of my predicted pareidolia faces across 10 images
-
of the 12, 10 had all of its facial feature landmarks reasonably placed in relation to the pareidolia face
-
of the 12, 2 had all of the facial features reasonably located, except the nose facial feature (fig 3 and fig 16)
-
-
detected 6 faces that were extremely off from my predictions across 5 images and all of the 6 detected faces had all of its facial features unreasonably placed from the last phase of the model
-
missed to detect 2 pareidolia faces, however was able to detect facial features in those two images (fig 1 and fig 2)
-
missed 1 pareidolia face in a multi-face pareidolia image
-
of the 6 multi-face pareidolia images, the model was able to detect faces in half of the images
It seems that the MTCNN model has problems detecting pareidolia faces with noses that are represented as two nostrils, because it needs to detect the tip of the nose and the two nostrils make it hard to detect the tip of the nose. The nose landmark feature seems to be the only facial feature that is ever off from all of the facial features that it detects. The model was able to detect pareidolia faces in images that have an immense amount of detail in the pareidolia face structure (except figure 19), more so than those with simple facial features, ie no shading and just circles and a line for a mouth. This makes sense, since it is essentially detecting human faces, just with a different skin texture, ie cheese mold in figure 9. In figure 9, it did better than me in identifying pareidolia faces in the image as it found the tiny pareidolia face on the top left of the big pareidolia Jesus face in the center.
Future Directions:
Even though the MTCNN model was able to detect some of the pareidolia faces, a future direction would be to explore the human face accuracy of the MTCNN model when it is trained on some images that induce pareidolia. However, due to lack of good quality images online that induce such an effect it will be difficult to aggregate the 1000 images needed for training such a model and another 100+ for the testing phase. Another possible future direction would be to explore the MTCNN model's ability to detect faces and facial features on human faces that don't have all of the facial features or have facial features that are not common among humans ie one eye or a cleft lip. This could explore the MTCNN model's nose sensitivity.
